Poverty Classification with Multi-Modal Data
What it does
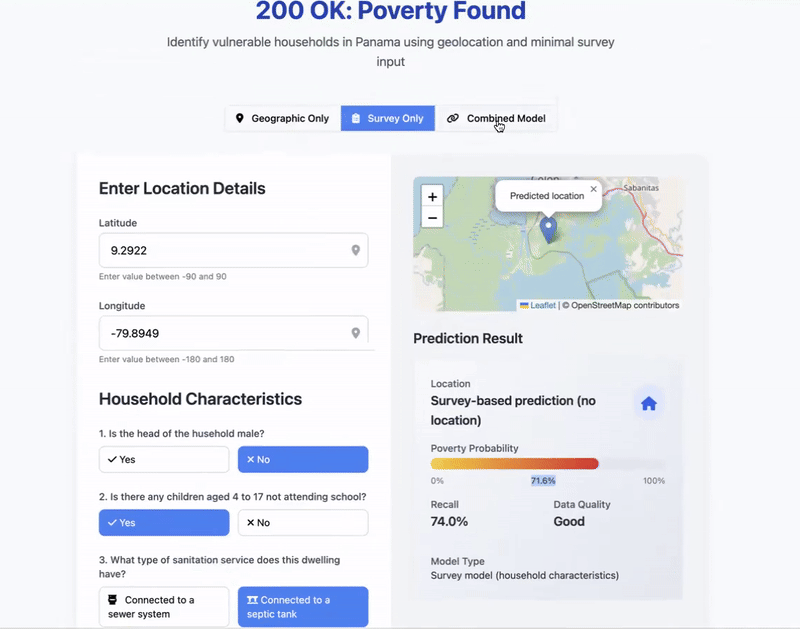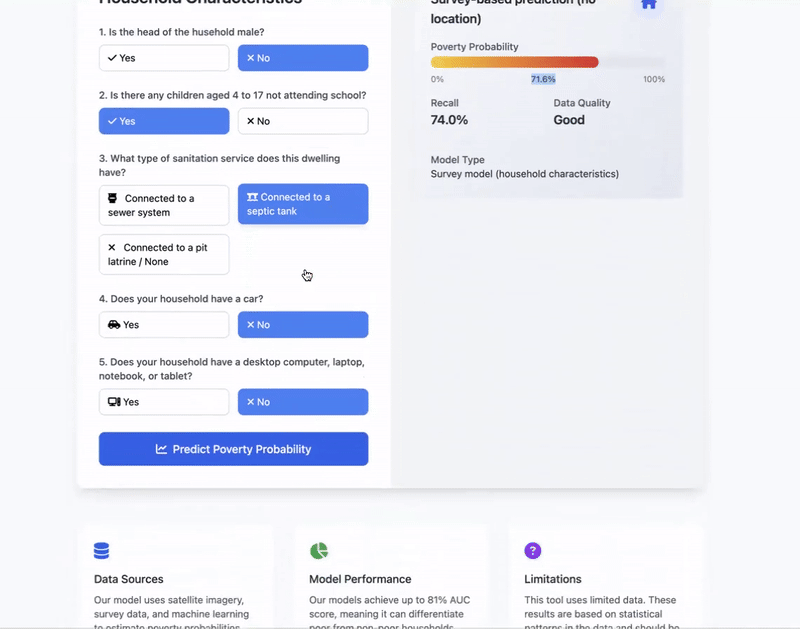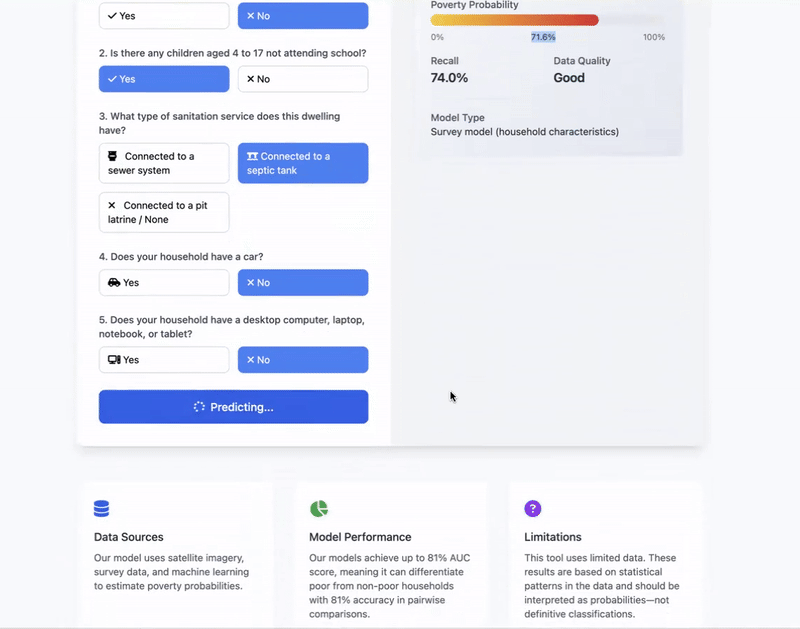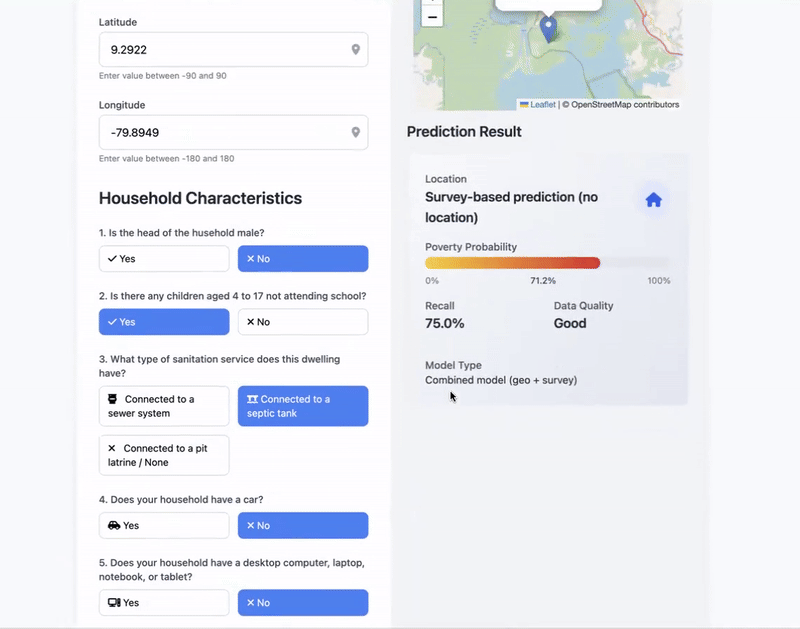
This project develops a hybrid machine learning framework to improve household-level poverty classification by integrating satellite-derived features and a minimal set of survey-based proxy means test (PMT) questions.
Why I made it
My motivation was grounded in the needs of governments and non-profit organizations that must target benneficiaries under tight budget constraints. Comprehensive living standards surveys are axpensive and slow, while purely geospatial methods lack granularity. By merging both approaches, this model enables two use cases:
- organizations with no field resources can generate reliable poverty estimates from geolocation alone;
- organizations with limited resources can improve targeting accuracy using 5 simple survey questions.
Tools & Technologies
- Feature extraction: MOSAIKS API, VIIRS API
- Database storage: Parquet, ChromaDB
- Geospatial analysis: shapely, geopandas
- Machine Learning: sklearn, interpretml
- Data Visualization: folium, matplotlib
- App Development: html, flask, webbrowser, threading
What I learned
- Working with high-resolution VIIRS data and MOSAIKS features.
- Deploying interpretable ML.
- Building full pipelines from model training to deployment.
- Creating interactive apps with an html front-end and hosted using flask.
Real-world use / impact
Used to demonstrate a low-cost poverty targeting prototype during a university presentation on data-driven development. The approach has potential to support NGOs and governments in allocating social resources more efficiently, especially in data-scarce settings.
Team
Built alongside Ángela López and César Nuñez as a final project of the CAPP30254 Machine Learning for Public Policy class.
🔗 Code
View on GitHub